













3 октября 2024 г.

Окончание. Начало тут
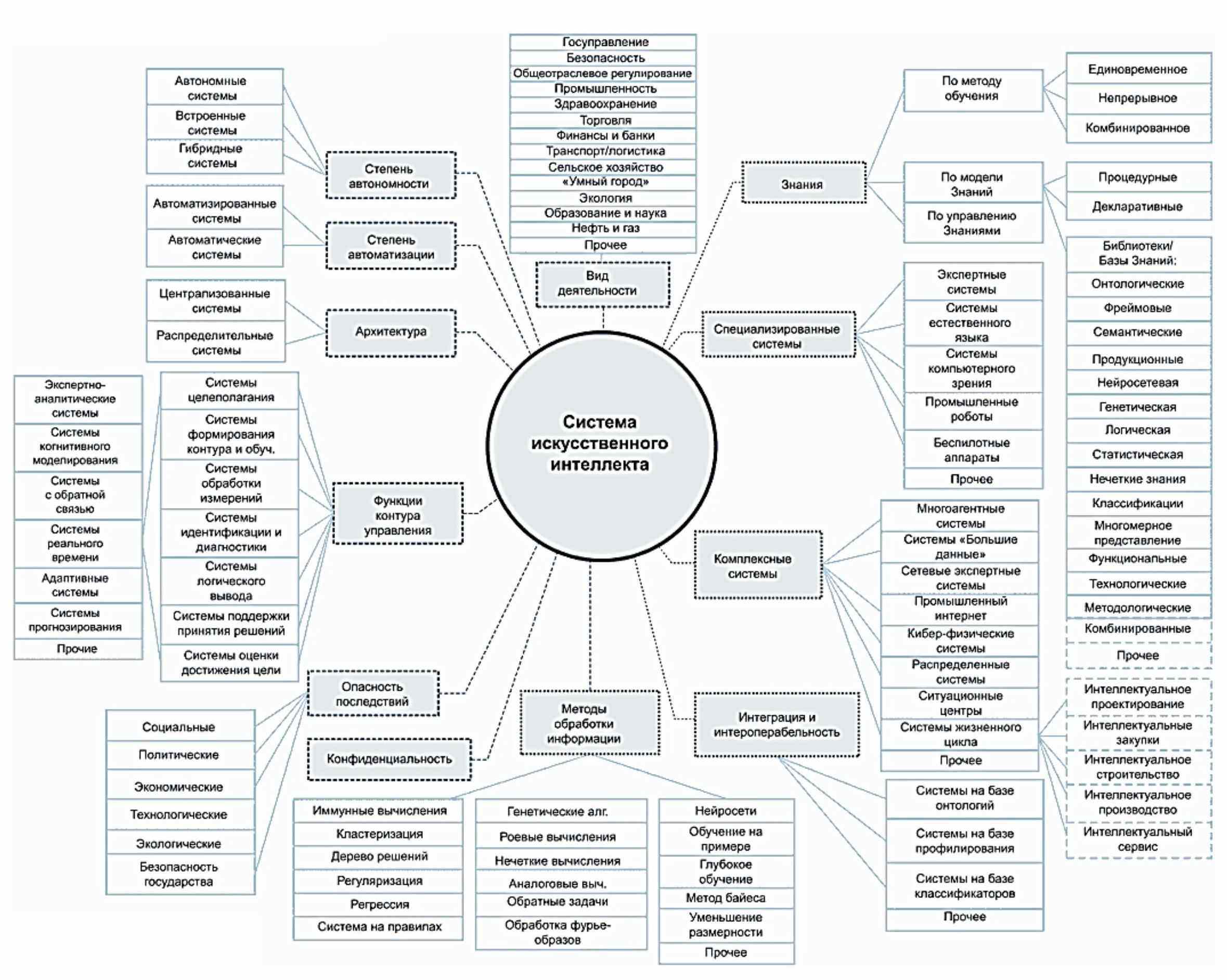
Проблемы классификации систем искусственного интеллекта
О важности развития технологий ИИ, среди прочего, говорит то, что одна из федеральных программ национального проекта «Экономика данных и цифровая трансформация государства» носит название «Искусственный интеллект». И, как было отмечено на недавнем «Восточном экономическом форуме», на реализацию данной программы в
Кроме того, существует «Национальная стратегия развития искусственного интеллекта на период до 2030 года», утвержденная Президентом РФ в октябре 2019 г. и скорректированная в феврале 2024 г. Это обновление отражает новые вызовы и акценты, такие как развитие технологий генеративного ИИ, расширение государственной поддержки научных исследований и разработок в области ИИ, а также усиление мер по международному сотрудничеству и информационной безопасности.
Текущую редакцию данной Стратегиии можно найти на сайте «Альянса в сфере искусственного интеллекта», объединяющего ряд крупных отечественных технологических компаний для совместного развития их компетенций и ускоренного внедрения искусственного интеллекта в образовании, научных исследованиях и в практической деятельности бизнеса.
По мнению Сергея Вотякова (председатель Комитета ИИ РУССОФТ, председатель Кластера РАЭК/RPA, директор по взаимодействию с органами государственной власти PIX Robotics), данная Стратегия потребует обновления через
При этом «перспективные методы искусственного интеллекта» определяются как «методы, направленные на создание принципиально новой научно-технической продукции, в том числе в целях разработки универсального (сильного) искусственного интеллекта (автономное решение различных задач, автоматический дизайн физических объектов, автоматическое машинное обучение, алгоритмы решения задач на основе данных с частичной разметкой и (или) незначительных объемов данных, обработка информации на основе новых типов вычислительных систем, интерпретируемая обработка данных и другие методы).
Кроме того, существует ГОСТ Р
Мнения разработчиков ПО
Однако ближе к делу. То есть к результатам нашего опроса. Руководитель продуктового направления «Расчеты. Электронные онлайн-платежи» компании «Диасофт» Сергей Добриднюк полагает: «В разработке ИИ-моделей очень важна верная постановка задачи. В то же время наблюдается острый дефицит экспертов по бизнесу, которые умеют решать задачи не традиционным , а „цифровым“ способом. Т. е. нужны кросс-доменные эксперты — с упором больше в практику. Потому что только они способны ставить верные гипотезы, а при помощи ИИ их подтверждать или опровергать. Может даже вообще составить в каждой сфере „задачи тысячелетия“ — как сделал Гилберт для математики в 1900, а потом дружно наваливаться их решать. И еще -— не исключено, что текущий путь „модели персептрона“ в принципе не соответствует реальным механизмам мышления человека. Это модель, но грубая. В прошлом году Джеффри Хинтон — гений, внесший кучу открытий в глубоком обучении, рассказывал — что архитектура глубокого обучения GAN (Generative adversarial network, генеративно-состязательная сеть) его сильно увлекла — в чем-то разочаровала, но в чем то и поразила. ChatGPT натолкнул его на проработку новых решений на новых математических, физических и инженерных принципах. Но конкретно как и куда надо идти он увы не сказал».
Тут, конечно, возникает вопрос: что необходимо сделать, чтобы в нашей стране стало больше кросс-доменных экспертов. Если не гениальных, то хотя бы просто талантливых. Ну да это тема отдельного разговора....
Менеджер по продукту UserGate Client Виталий Даровских рассказал: «Для нас актуальны специалисты, должности которых можно обозначить так: ML Product;
А руководитель Центра мониторинга и реагирования UserGate Дмитрий Кузеванов добавил: «Использование нейросетевых технологий и алгоритмов машинного обучения для выявления и нейтрализации вредоносного ПО — это правильный прогрессивный путь развития, по которому идет большинство, если не все компании, которые работают в сфере информационной безопасности. Мы уделяем большое внимание разработке и тестированию
Дмитрий Серый, заместитель директора и соучредитель компании Vinteo, отмечает: «Можно выделить несколько ключевых ИИ-компетенций, которые наиболее востребованы среди компаний, занимающихся разработкой заказного и/или тиражируемого ПО. В первую очередь, это специалисты с навыками создания, оптимизации и интеграции моделей машинного обучения и глубокого обучения для решения различных задач — от анализа данных до разработки интеллектуальных систем. Также требуется высокая квалификация в области компьютерного зрения для разработки систем, способных анализировать и интерпретировать изображение и видео, в направлении анализа больших данных и систем, основанных на NLP — они используются в чат-ботах, системах поддержки клиентов и инструментах для анализа текстов.
Если говорить о профессиональных решениях видеоконференцсвязи, то сейчас в российском сегменте ВКС-решений технологии искусственного интеллекта решают в первую очередь задачи распознавания речи и образов. Нередко эти задачи решаются в партнерстве. Так например, в технологическом партнерстве с группой компаний ЦРТ мы cоздали совместное решение для интеллектуального сопровождения ВКС-совещаний, дополняющее функционал сервера видеоконференций VINTEO современными технологиями распознавания речи с автоматической подготовкой стенограмм. А компания Neutronix создала на базе VINTEO решение по видеоаналитике ВКС в режиме онлайн, которое в динамическом режиме умеет автоматически идентифицировать каждого участника видеовстречи и показывать единую информацию о нем, позволяет заходить в конференц-комнату, просто посмотрев в камеру, собирает аналитику и показывает разноплановую статистику, в зависимости от запросов заказчика».
Из сказанного выше следует, что создание программных продуктов, использующих те или иные технологии ИИ, требует хорошо скоординированной работы не только «айтишников», но и специалистов самых различных специальностей. В качестве примера можно привести ООО «Таймлист», разработчика лингвистического ПО, использующего технологии ИИ для обработки естественного языка. В штате этой компании соотношение между профессиональными лингвистами (то есть людьми, окончившими в своё время лингвистические факультеты тех или иных вузов) и профессиональными «айтишниками» (выпускниками ИТ-факультетов ведущих технических вузов) составляет примерно 20/80.
О проблемах, связанных с использованием технологий ИИ, соучредитель и директор по маркетингу «Таймлист» Владислав Бешляга говорит так: «В современном мире нейросети устроены таким образом, что чем больше данных им предоставить, тем умнее они становятся. Архитектура нейросетей в большей степени понятна, сегодня основное значение имеют объём данных и степень обученности модели. Поэтому очень велика роль специалистов по подготовке обучающих датасетов. Их в резюме или вакансиях часто обозначат как „специалистов по разметке данных“, „редакторов текстов для нейросетей“ и так далее. Эти люди должны иметь как ИИ-квалификации, так и познания в соответствующей предметной области. Также желательно, чтобы они имели определенные познания в области науки о данных (Data Science).Такого рода людей некоторые Job-сервисы, см., например здесь, относят к категории „дата-сайентистов“ или DS-специалистов».
О важности правильной организации данных, на основе которых принимаются те или иные решения, говорилось и во время круглого стола «Повышение уровня готовности российской экономики к внедрению искусственного интеллекта через эффективную работу с данными и бизнес-процессами», который в рамках «Международного технологического конгресса 2024», состоявшегося
Источник: IT Channel News
